PhD thesis · eLife reviewed preprint · Naturalistic fMRI · Multimodal modeling
Naturalistic neural encoding in autism
I built a preregistered multimodal modeling pipeline that linked real-world movie features to whole-brain fMRI responses in 171 children and adolescents. The project tested where sensory and higher-level visual information are represented differently in autism, revealing a shift in feature weighting in pSTS and nearby social/integration cortex rather than a broad early-sensory enhancement effect.
- Dataset
- 171 children and adolescents from the Healthy Brain Network
- Data
- 15-minute naturalistic movie-viewing fMRI
- Modeling
- Stacked ridge regression encoding models
- Scale
- 280M+ grayordinate-wise model fits
- Inference
- Cross-validation, permutation testing, FDR correction, preregistered hypotheses, multi-threshold motion QC
- Output
- eLife reviewed preprint + Harvard dissertation
Project snapshot
Many neuroscience studies use simplified stimuli or tightly controlled tasks. I wanted to test whether we could model brain responses to rich, naturalistic audiovisual input while still making statistically rigorous and interpretable claims.
This became a large-scale supervised learning and inference problem: transform continuous movies into aligned feature spaces, predict cortical fMRI responses, estimate how different feature classes contribute to those predictions, and test whether those representational profiles differ by diagnosis, age, and symptom burden.
What I built
- Extracted and aligned multimodal audio and visual features from naturalistic movie stimuli.
- Built feature banks spanning low-level sensory structure and higher-level semantic/social content.
- Fit whole-brain encoding models to predict cortical fMRI responses from each feature space.
- Combined feature-specific models using stacked encoding to estimate relative feature weighting.
- Tested group, developmental, and symptom-related effects using preregistered analyses, FDR correction, and multiple motion-quality thresholds.
- Validated model behavior against expected sensory organization before interpreting autism-related differences.
Modeling pipeline
The core technical task was to turn a naturalistic movie into structured feature timelines, predict brain responses from each feature space, and compare how different kinds of information were weighted across cortex.
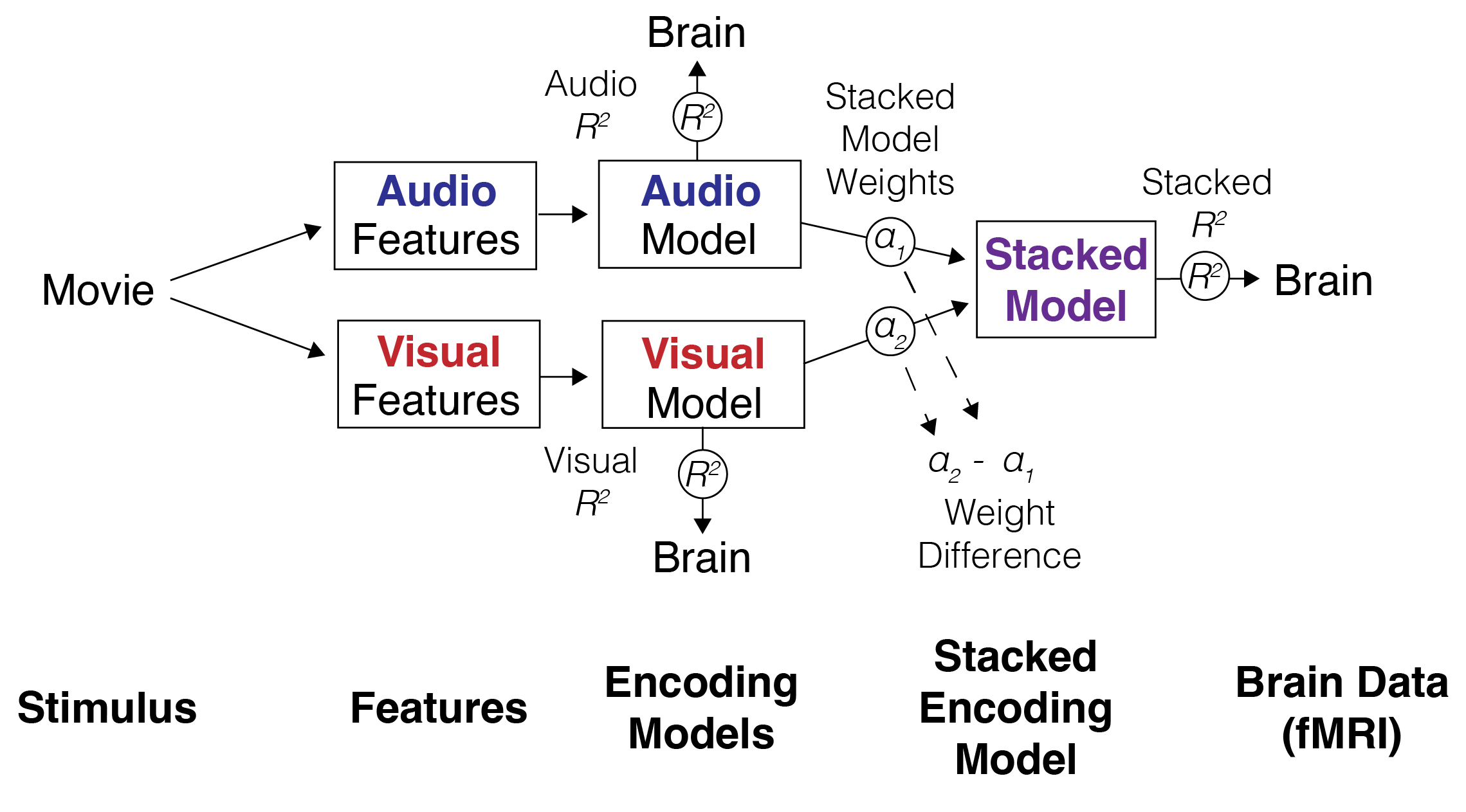
Key result
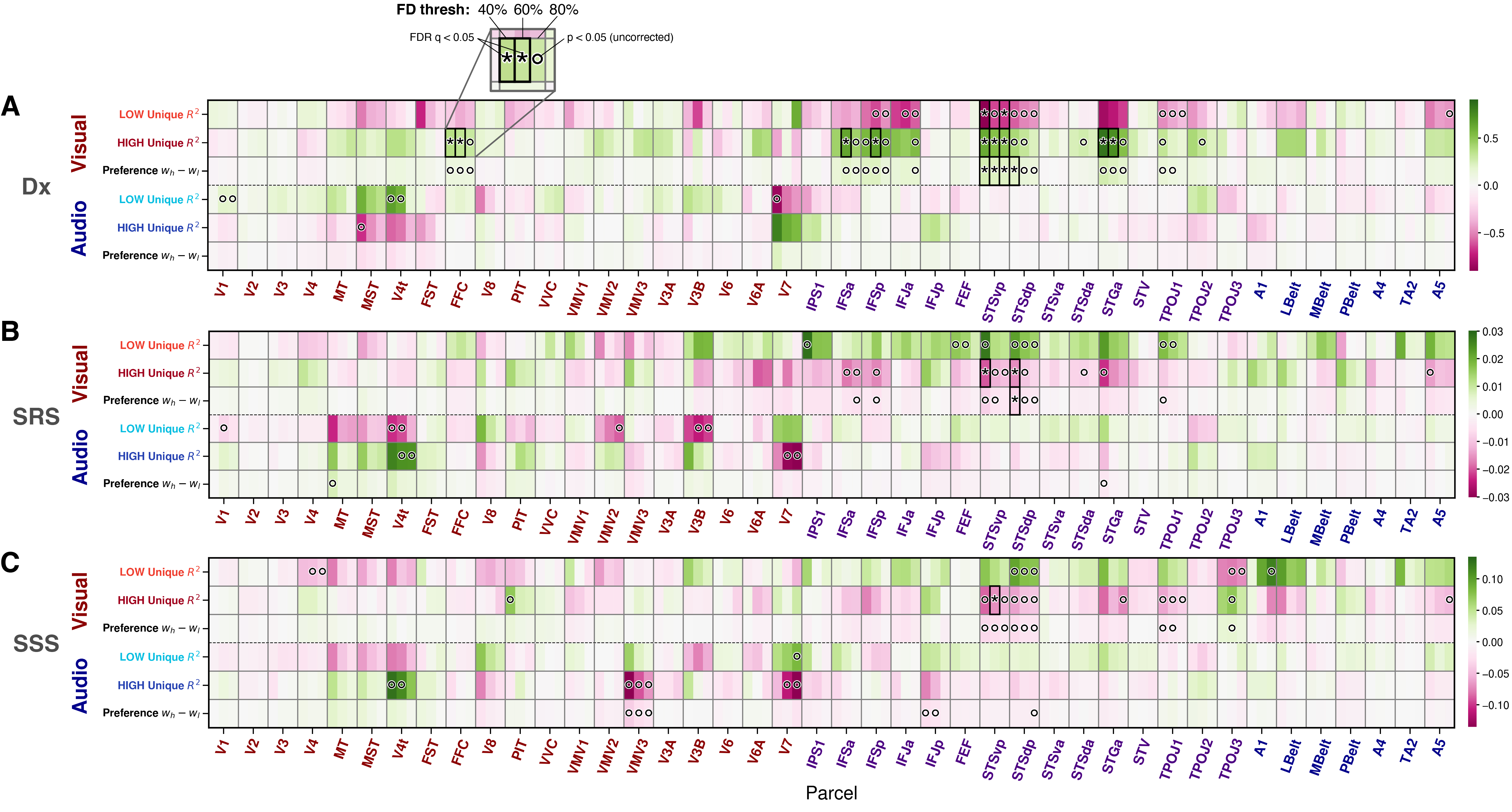
The main finding was not a simple global increase in sensory responsiveness. Instead, autism-related differences were localized to how higher-order visual information was weighted in social and multisensory integration regions.
- No evidence supported the preregistered prediction that autism would show enhanced low-level encoding in primary sensory cortices.
- In pSTS and nearby social/integration cortex, autistic participants showed a relative shift toward lower-level over higher-level visual feature encoding.
- High–low visual weighting in pSTS tracked autism-related social phenotype.
- Audio–visual modality balance was broadly conserved across groups.
- Developmental effects were prominent, showing strong age-related changes in encoding and modality tuning.
See technical result summary
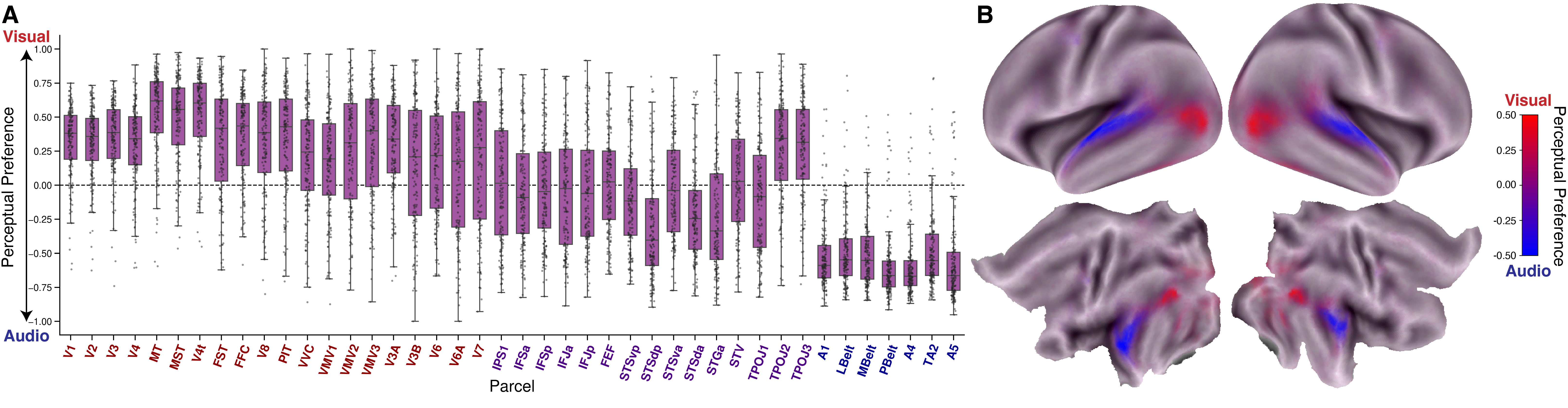
Model validation
Before interpreting group differences, I checked whether the model behaved as expected across known sensory systems.
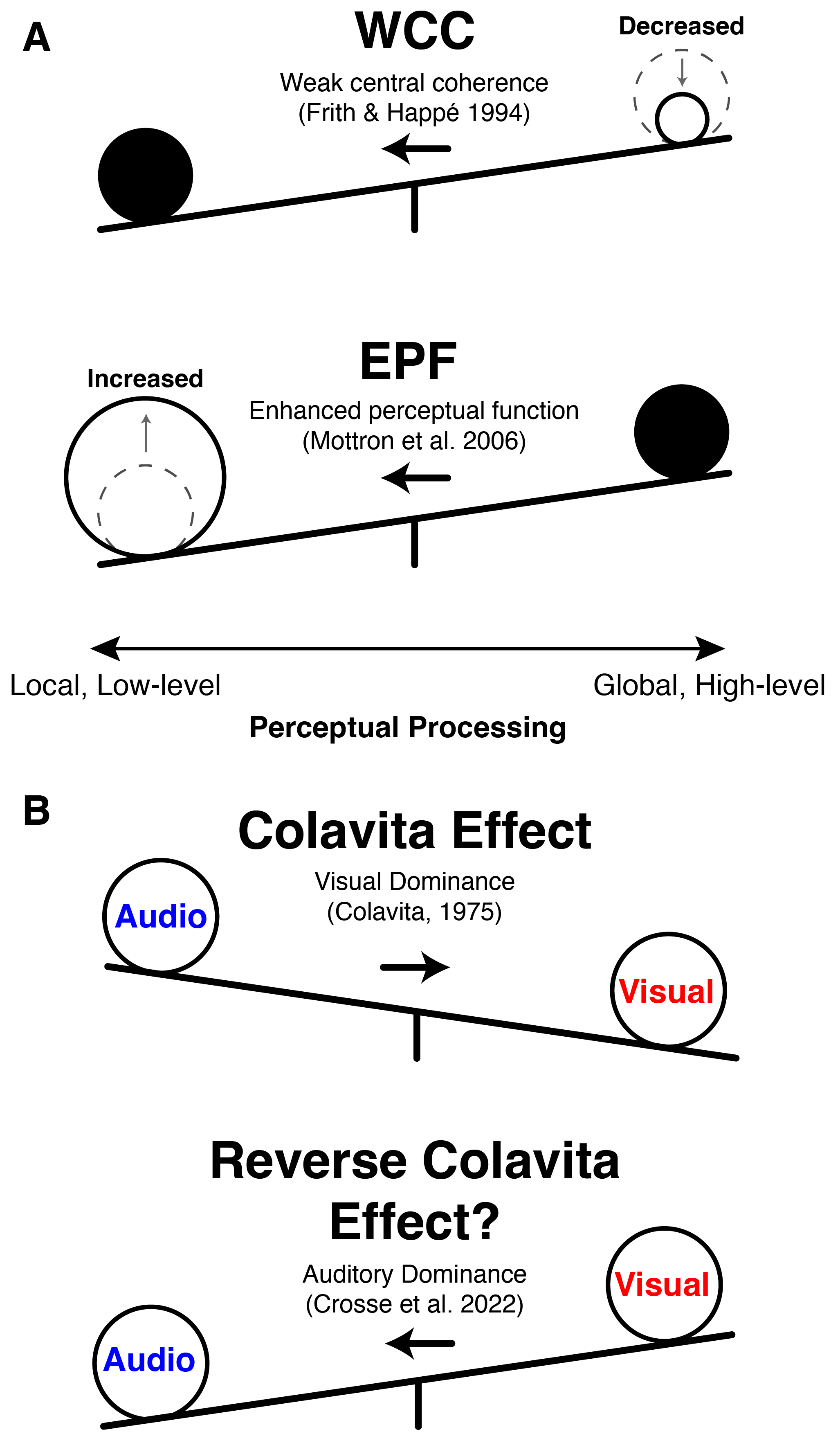
Technical approach
Multimodal feature engineering
Converted continuous movie stimuli into synchronized visual and auditory feature timelines, including low-level visual structure, higher-level visual content, low-level audio, speech/music, and other interpretable feature classes.
Predictive modeling
Fit feature-specific ridge encoding models and combined them with stacked models to estimate both predictive performance and the relative contribution of competing feature banks.
Statistical validation
Used held-out prediction, permutation testing, FDR-controlled inference, preregistered hypotheses, and repeated motion-threshold analyses to separate robust effects from noise and data-quality artifacts.
Interpretability
Reduced complex model outputs into interpretable cortical summaries, feature-weighting metrics, visualizations, and plain-language conclusions.
Scientific framing
This study translated long-standing theories of autistic perception into testable model comparisons: low- versus high-level feature encoding and auditory versus visual feature weighting during movie viewing.
Why this matters beyond neuroscience
For me, this project was also a testbed for applied machine learning on messy, high-dimensional human data.
- Built predictive pipelines for noisy multimodal time-series data.
- Translated unstructured real-world inputs into analysis-ready features.
- Designed interpretable models rather than treating prediction as a black box.
- Balanced data quality, sample size, model complexity, and statistical confidence.
- Communicated nuanced results, including negative findings, without oversimplifying.
- Worked across neuroscience, machine learning, clinical research, and open-science constraints.
My role
I drove this project from idea to manuscript. I framed the research questions, reviewed the literature, developed the preregistered analysis plan, implemented the modeling pipeline, ran the statistical analyses, interpreted the results, and wrote the dissertation/manuscript.
My technical contributions included multimodal feature construction, stacked encoding model development, large-scale model fitting, cortical summarization, motion-threshold robustness analyses, FDR-controlled inference, visualization, and result interpretation.
I worked with collaborators and advisors at MIT, Harvard, and UBC/BC Children’s Hospital, whose guidance and feedback strengthened the scientific framing, interpretation, and final paper.
Publication and thesis
This project is the central empirical work from my Harvard PhD dissertation and is now available as an eLife reviewed preprint.
- Mentch J, Chen Y, Vanderwal T, Ghosh SS. “Pregistered movie-fMRI analyses reveal altered visual feature encoding in autism in pSTS.” eLife reviewed preprint. DOI: 10.7554/eLife.111008.1.
- Mentch JS. “Sensory Feature Representation in Autism: Insights From Naturalistic Neuroimaging.” Harvard University dissertation, 2026.